NeRF-Supervised
Deep Stereo
CVPR 2023
|
|
|
|
|
|
|
|
|

|
On top, predictions by RAFT-Stereo trained with our approach on user-collected images, without using any synthetic datasets, ground-truth depth or (even) real stereo pairs. At the bottom, a zoom-in over the Backpack disparity map, showing an unprecedented level of detail compared to existing strategies not using ground-truth trained with the same data. |
"We introduce a novel framework for training deep stereo networks effortlessly and without any ground-truth. By leveraging state-of-the-art neural rendering solutions, we generate stereo training data from image sequences collected with a single handheld camera. On top of them, a NeRF-supervised training procedure is carried out, from which we exploit rendered stereo triplets to compensate for occlusions and depth maps as proxy labels. This results in stereo networks capable of predicting sharp and detailed disparity maps. Experimental results show that models trained under this regime yield a 30-40% improvement over existing self-supervised methods on the challenging Middlebury dataset, filling the gap to supervised models and, most times, outperforming them at zero-shot generalization." |
Method
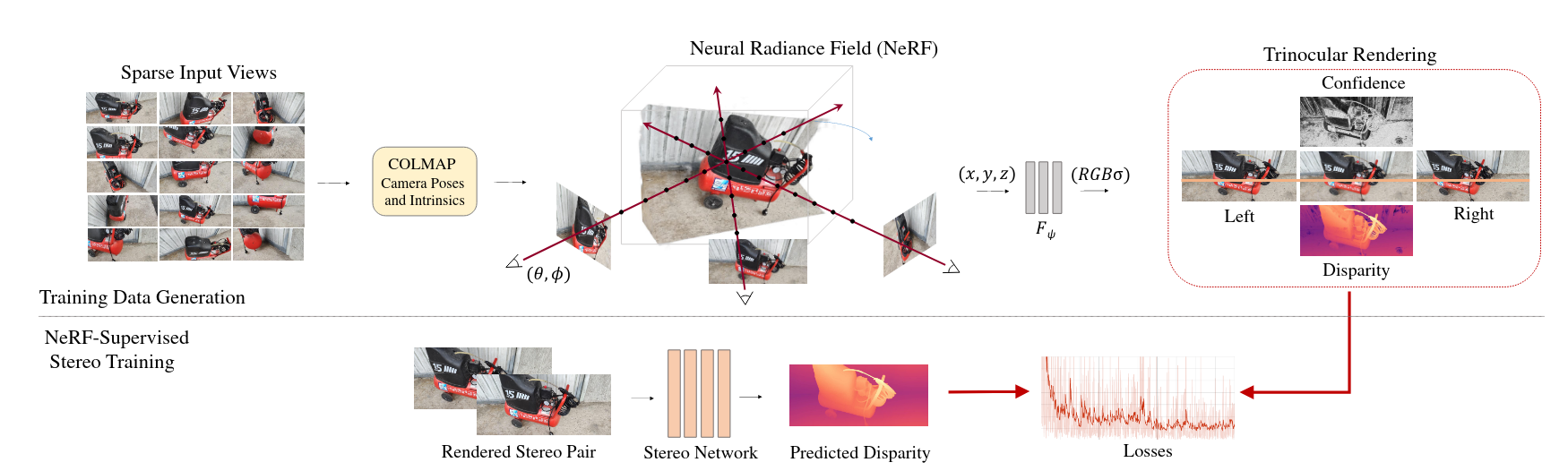 |
1 - Training Data Generation
2 - NeRF-Supervised Stereo RegimeData generated so far is used to train stereo models. Given a rendered image triplet \((I_l, I_c, I_r)\), we estimate a disparity map by feeding the network with \((I_c, I_r)\) as the left and right views of a standard stereo pair. Then, we propose an NS loss with two terms:
|
Youtube Video
|
|
Collected Dataset
We collect a total of 270 high-resolution scenes (≈8Mpx) in both indoor and outdoor environments using standard camera-equipped smartphones . For each scene, we focus on a/some specific object(s) and acquire 100 images from different viewpoints, ensuring that the scenery is completely static. The acquisition protocol involves a set of either front-facing or 360◦ views. Here we report individual examples derived from 30 different scenes that comprise our dataset. |
 |
Coming Soon: Upload Your Scene!
Would you like to contribute to expanding our dataset in order to obtain more robust and accurate stereo models in every scenario? Upload your images via a zip file, and we will take care of processing them using NeRF and retraining the stereo models. (STILL WORK IN PROGRESS) |
 |
Qualitative Results
 |
From left to right: reference image and disparity map obtained by training RAFT-Stereo using the popular image reconstruction loss function between binocular stereo pairs \( \mathcal{L}_\rho \), the photometric loss between horizontally aligned triples \( \mathcal{L}_{3\rho} \), disparity supervision from proxy labels extracted using the method proposed in Aleotti et al. [3], and our NeRF-Supervised loss paradigm. |
 |
Qualitative results on ETH3D. We show reference images and disparity maps predicted by RAFT trained using our NeRF-Supervised loss paradigm. |
BibTeX
@inproceedings{Tosi_2023_CVPR,
author = {Tosi, Fabio and Tonioni, Alessio and De Gregorio, Daniele and Poggi, Matteo},
title = {NeRF-Supervised Deep Stereo},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {855-866}
}* This is not an officially supported Google product. |